Summary of a talk delivered at Apache Beam Digital Summit on August 4, 2021.

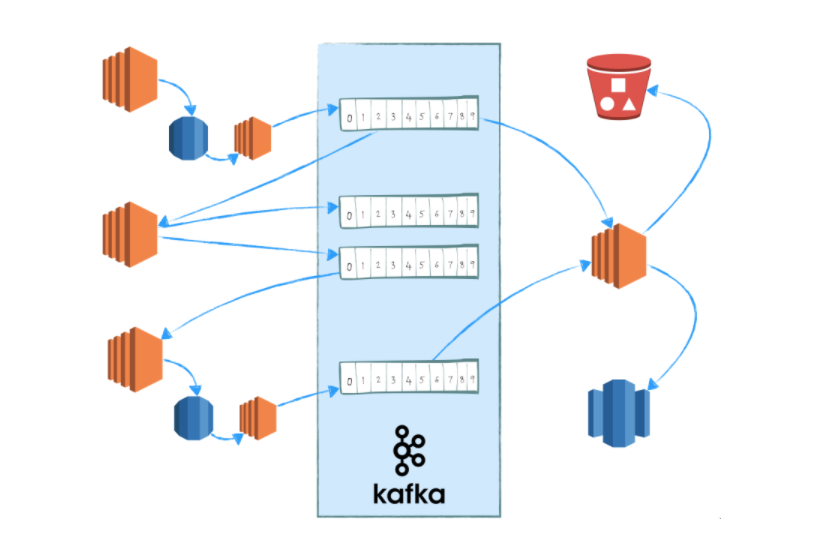
This session will start with a brief overview of the problem of duplicate records and the different options available for handling them. We’ll then explore two concrete approaches to deduplication within a Beam streaming pipeline implemented in Mozilla’s open source codebase for ingesting telemetry data from Firefox clients.
We’ll compare the robustness, performance, and operational experience of using the deduplication built in to PubsubIO vs. storing IDs in an external Redis cluster and why Mozilla switched from one approach to the other.
Finally, we’ll compare streaming deduplication to a much stronger end-to-end guarantee that Mozilla achieves via nightly scheduled queries to serve historical analysis use cases.