Originally posted on the Simple engineering blog; also presented at PGConf US 2017 and Ohio LinuxFest 2017
We previously wrote about a pipeline for replicating data from multiple siloed PostgreSQL databases to a data warehouse in Building Analytics at Simple, but we knew that pipeline was only the first step. This post details a rebuilt pipeline that captures a complete history of data-changing operations in near real-time by hooking into PostgreSQL’s logical decoding feature. The new pipeline powers not only a higher-fidelity warehouse, but also user-facing features.
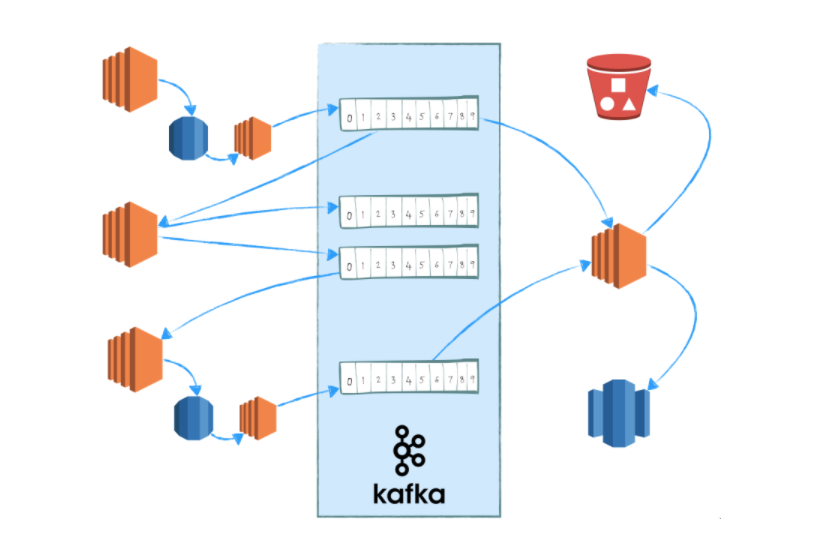
A brief overview of PostgreSQL, Kafka, and Redshift
PostgreSQL is a relational database, modeling data as a collection of tables with well-defined schemas which we typically access and modify via an SQL interface. The tables at the SQL layer are only part of the story, though. Under the hood, PostgreSQL provides data integrity by committing data changing operations first to a WAL (Write-Ahead Log) before modifying the tables we access via SQL. If the database halts midway through an update of user-facing relations, it is able to recover to a consistent state by replaying changes from the WAL. From a consistency perspective, the log of committed data changes modeled in the WAL is the source of truth about the state of a PostgreSQL instance and the tables are merely a conveniently queryable cache of the log.
Enter Apache Kafka—a data store that puts this same idea of a durable, immutable, ordered log of data changes front and center. In Kafka, a log is called a “topic partition”, and a set of partitions distributed across multiple nodes can be grouped together into a logical “topic”. Kafka clients produce to and consume from these topics directly rather than through a more abstract interface like SQL. The simplicity of this model and the distributed architecture allows a single Kafka cluster to scale and serve as the backbone of a streaming data platform.
Redshift is AWS’s fully managed data warehouse offering with a SQL interface that will be very familiar to PostgreSQL users. The performance characteristics are very different from PostgreSQL, however, with each table’s data stored in a compressed columnar format and distributed across potentially dozens of nodes. Data changing operations are optimized for bulk transfers and the query planner is optimized for efficient aggregations. We published a detailed account of Simple’s use of Redshift in our previous post.
Components of the pipeline
Exporting a full stream of changes from a database based on its commit log is known as change data capture or CDC. Since version 9.4, PostgreSQL exposes a CDC interface called logical decoding. Users define an output format by writing a logical decoding output plugin in C that gets access to the internal PostgreSQL structures representing a data change. Once a logical decoding plugin is in place, clients can connect to a replication slot and receive messages in their specified format.
Simple maintains their own logical decoding plugin called wal2json (forked from the open source https://github.com/eulerto/wal2json) and a service for interacting with it called pgkafka. pgkafka consumes from a PostgreSQL replication slot and produces messages to a Kafka broker.
To make this more concrete, let’s consider a service that processes user transactions. It stores transaction information to a very simple table called transactions defined as:
CREATE TABLE transactions (
transaction_id INT PRIMARY KEY,
user_id INT,
amount INT
);
Now, let’s insert a row into that table:
INSERT INTO transactions VALUES (54441, 36036, 2000);
An instance of pgkafka subscribed to a logical decoding slot will produce the following message to Kafka:
{
"lsn": 2233445,
"xid": 1126636,
"operation": "insert",
"table": "public.transactions",
"timestamp": "2017-02-26 18:20:33.957474+00",
"columns": ["transaction_id", "user_id", "amount"],
"types": ["int4", "int4", "int4"]
"values": [54441, 36036, 2000]
}
The content of the row is defined by the “columns”, “values”, and “types” entries. The rest of the fields give metadata about how PostgreSQL tracks the change. In particular, note the “lsn” field which gives the Log Sequence Number (LSN) of the change, the byte offset within the WAL at which the data is recorded. This unique, ordered identifier is important for downstream systems as we’ll discuss in the next section.
Next, let’s update the row and delete it:
UPDATE transactions SET amount = 2500 WHERE transaction_id = 54441;
DELETE FROM transactions WHERE transaction_id = 54441;
pgkafka will emit the following two messages:
{
"lsn": 2233585,
"xid": 1126637,
"operation": "update",
"table": "public.transactions",
"timestamp": "2017-02-26 18:21:35.278491+00",
"columns": ["transaction_id", "user_id", "amount"],
"types": ["int4", "int4", "int4"]
"values": [54441, 36036, 2500],
"identity":{
"columns": ["transaction_id"],
"types":["int4"],
"Values":[54441]
}
}
{
"lsn": 2233715,
"xid": 1126638,
"operation": "delete",
"table": "public.transactions",
"timestamp": "2017-02-26 18:22:03.190093+00",
"identity":{
"columns": ["transaction_id"],
"types":["int4"],
"values":[54441]
}
}
These messages contain an “identity” field that was absent from the INSERT operation. Each table in PostgreSQL has a REPLICA IDENTITY indicating which values from the previous version of a row should be recorded on each UPDATE or DELETE. By default, this is equal to the table’s primary key as seen above.
Delivery guarantees
At a high level, a pipeline will usually provide a guarantee of “at most once”, “at least once”, or “exactly once” delivery. “Exactly once” is the ideal, but achieving such a guarantee is difficult to impossible, especially when pieces of the system are distributed and lack strong transactional behavior. In particular, current versions of Kafka do not support any producer configuration that can guarantee exactly once delivery in all cases. For our needs, losing messages is unacceptable, so we have pursued an overall pipeline design that ensure “at least once” delivery.
Settling for “at least once” semantics means accepting that duplicate records are going to arrive in downstream systems. We mitigate duplicates in this pipeline by taking advantage of the “lsn” field provided by PostgreSQL, which can act as a unique and globally ordered identifier. The uniqueness of the identifier allows us to identify duplicate records and remove them. LSN always increases as PostgreSQL commits transactions, so even if messages arrive out of order to Kafka, we can restore order in a downstream system by sorting on LSN.
Applications
Asynchronous communication between services
Our backend services present REST APIs for communication with clients and other services and they have also historically used RabbitMQ for notifications to other services. More recently, Kafka has become our message queue of choice, pushing RabbitMQ to legacy system status. Kafka’s durability and ordering guarantees alone make it a compelling alternative to RabbitMQ for many applications. The pgkafka pipeline, however, means that services never have to explicitly publish to a message queue at all. This is great for reducing the number of technologies we need to think about, but even better for its flexibility. When we discover a new case where a feed from another service is needed, the relevant data is often already being saved to a PostgreSQL table, meaning that it’s already available as a feed via pgkafka.
Replicating database change history to Redshift
Database streams from pgkafka persisted to Redshift have become the dominant data source for analytics across our company. For each PostgreSQL table flowing through pgkafka, we create a change history table in Redshift. For the transactions table discussed above, the corresponding table in Redshift is defined as:
CREATE TABLE pgkafka_txservice_transactions (
pg_lsn numeric(20,0) ENCODE raw,
pg_txn_id bigint ENCODE lzo,
pg_operation char(6) ENCODE bytedict,
pg_txn_timestamp timestamp ENCODE lzo,
transaction_id INT ENCODE lzo,
user_id INT ENCODE lzo,
amount INT ENCODE lzo
)
DISTKEY user_id
SORTKEY (pg_lsn);
This definition is similar to the source table, but includes PostgreSQL metadata fields and Redshift-specific properties like column encodings and a distribution key.
Persisting the full change history allows for tremendous flexibility in analysis. We have been able to avoid adding in history tables and triggers in our backend PostgreSQL instances to satisfy new data compliance or query requirements because the history was already persisted in Redshift. However, most analyses don’t need to roll back through history and are instead concerned with understanding the current state of our backend data.
We put views of top of each pgkafka table in Redshift that utilize our knowledge of the table’s primary key as well as the metadata columns in order to filter out rows that no longer represent the most recent state. In the transactions case, this view looks like:
CREATE VIEW current_txservice_transactions AS
SELECT transaction_id, user_id, amount FROM (
SELECT *, ROW_NUMBER() OVER
(PARTITION BY transaction_id
ORDER BY pg_lsn DESC, pg_operation DESC) AS n
FROM pgkafka_txservice_transactions
)
WHERE n = 1
AND pg_operation <> 'delete';
Stream processing
Most of our current uses of change data capture are fairly direct: an application subscribes to a topic like txservice-postgres, filters down to just the table the application cares about, and then takes action on the records. A new phase of our analytics infrastructure, however, is deploying applications on top of the Kafka Streams library to create derived streams for downstream consumption.
By default, a Kafka topic has a 7-day retention period, but Kafka also offers the option of specifying a compaction policy rather than time-based retention. A compacted topic will save the most recent record for any given key per partition, so old records are only cleaned up if a newer record with the same key arrives. This concept is perfect for modeling the current state of a database table if the keys of Kafka messages are set as the value of each row’s primary key columns. Kafka Streams takes advantage of that concept by allowing users to model a Kafka topic as either a KStream (non-compacted) or a KTable (compacted) with semantics defined for several different kinds of joins between them. We plan, for example, to build Kafka Streams applications that denormalize data and provide output streams more easily ingestible for analysis.
Comparison to Bottled Water
pgkafka treads on the same ground as the open source Bottled Water, so why is Simple maintaining its own solution? The reason is partly historical; we had started working on this pipeline before Bottled Water was released (and we were excited to see our own Xavier Stevens cited in the Bottled Water announcement post for his early prototypes). We’ve also made some different design decisions, which we’ll explore.
The most obvious difference between these two projects is data serialization – Bottled Water uses Apache Avro (with an option to emit JSON) whereas pgkafka uses JSON. Avro is capable of sending a compact binary representation over the wire and enforcing rigid schemas. We’re evaluating the benefits of adopting a serialization format like Avro, but Simple runs mostly on JSON for the time being and we have not set up infrastructure like a schema registry for Avro.
The content of messages sent to Kafka also differs in topic layout, key content, and message content. pgkafka produces to a single topic per database where the key for each message is the PostgreSQL LSN and the value is the JSON structure we discussed above. Bottled Water produces to a separate topic for each PostgreSQL table, setting the key of each message to the value of that row’s primary key columns and the value of the message to a flat representation of the values of all columns. If we consider the same INSERT, UPDATE, and DELETE that we performed earlier, Bottled Water with JSON output would produce 3 Kafka messages all with the same key:
{
"transaction_id": {
"int": 54441
}
}
And with the following three values:
{
"transaction_id": {"int": 54441},
"user_id": {"int": 36036},
"amount": {"int": 2000}
}
{
"transaction_id": {"int": 54441},
"user_id": {"int": 36036},
"amount": {"int": 2500}
}
null
Note how a DELETE is modeled as a null value, which is how clients flag to Kafka that messages associated with that key are eligible for log compaction.
Bottled Water’s format is definitely more convenient; it’s simpler, it’s ideal for the behavior of Kafka’s topic compaction feature, and in most cases a single table is what downstream applications are looking to consume. The more complex pgkafka data format pushes processing responsibility downstream, but also enables some important advantages relative to Bottled Water, namely the ability to deduplicate in a destination system based on PostgreSQL metadata columns and global ordering of changes across tables.
When we have need of a table-specific stream for performance or for storing the full state in a compacted topic, we use an additional service to consume from the source topic, demultiplex to specific tables, and save those to an output topic keyed on primary key rather than LSN, essentially giving us most of the benefits of Bottled Water’s format in an extra step.
Concerns and future enhancements
We first put this pipeline into our production environment over a year ago, slowly rolling it out to larger and larger services, learning some lessons along the way. One failure scenario we’ve observed for this pipeline is stress caused by a single transaction committing a large quantity of data. Since logical decoding does not emit pending records until their enclosing transaction commits, a single long-running and complex transaction can lead to a large batch of records flowing into the pipeline at once. Likewise, a schema update that sets a default value for a new column will emit a logical decoding message for each updated record, stressing the pipeline for large tables. Behavior of pgkafka has become something we need to consider when planning schema migrations and we may need to temporarily turn replication off in the future in order to handle migrations on large tables.
On the Redshift side, the “current” views we provide on top of history tables, while convenient, have not performed well for large data volumes. The views require a scan over the entire table to determine the most recent record for each primary key and potentially materialize a large intermediate result set, so this approach has not performed well for our largest tables. We have considered materializing these views explicitly to tables either through a nightly process or as part of the incremental loads we do throughout the day. Neither is ideal, as nightly materialization would lead to stale data compared to the views while materializing during incremental loads would add complexity and expense to the loading process.
Our use of this pipeline for analytics currently focuses on Redshift, but we are planning to expand our potential analytics toolset by storing our pgkafka streams to a data lake in S3. The data lake will allow us to offload some workloads from Redshift to batch processing tools like Spark or Presto. It will also give us flexibility in setting data retention policies in Redshift, since we will be able to confidently delete tables in Redshift, knowing that we can always restore from the audit history stored in S3.
The most exciting new direction for this project is enabled by the release of a replication protocol API with version 42.0.0 of the PostgreSQL JDCB driver. Most of Simple’s backend services are written in Scala, but there were no options for interacting with a PostgreSQL replication slot when we were writing pgkafka, leaving us with a codebase in C that we’ve struggled to improve, test, and monitor. We are currently pursuing a new version of pgkafka in Scala including an extensive Docker-based test suite, allowing us to verify delivery guarantees in a variety of failure scenarios and iterate much more safely and quickly. As the project matures, we will look into into releasing pgkafka along with our wal2json output plugin as open source software.